谷歌文生图巅峰之作 Imagen 2 登场,实测暴打 DALL・E 3 和 Midjourney

新智元报道
编辑:编辑部
【新智元导读】卷疯了卷疯了,谷歌刚刚放出了文生图 AI 模型的巅峰之作 Imagen 2,实测效果逼真细腻,生成的美女图仿佛真人照片,对于提示的还原程度已经打败了 DALL・E 3 和 Midjourney!最强文生图大模型这是要易主了?
提问:下面这张图,是 AI 生图还是照片?

如果不是这么问,绝大多数人大概都不会想到,这居然不是一张照片。
是的,只要在谷歌最新 AI 生图神器 Imagen 2 中输入这样的提示词 ——
A shot of a 32-year-old female, up and coming conservationist in a jungle; athleticwith short, curly hair and a warm smile
一位 32 岁的年轻女性自然保护主义者,正在丛林中探险。她体格健壮,一头短卷发,面带亲切的微笑
就能得到开头那张无比逼真写实、比照片还像照片的图像了!
虽然圣诞节已经临近,但谷歌还在卷个不停 —— 号称 DALL・E 3 最强竞品的文生图模型 Imagen 2,终于重磅上线了。
刚用 Gemini 和 OpenAI 卷完 GPT-4,立马又放出 Imagen 2 来卷 DALL・E 3 了,2023 年底的「卷王」称号,谷歌是实至名归。

不仅手指逼真,而且拿筷子的姿势也很标准
可以说,Imagen 2 是目前文本转图像技术的巅峰之作,已经突破了 AI 生图的界限。
在机器学习算法强大功能的加持下,Imagen 2 可以将文本描述转换为生动清晰的高分辨率图像。
Imagen 2 最与众不同之处在于,它能够以惊人的准确性,理解复杂抽象的概念,然后把这个概念可视化,细腻之程度令人惊叹!

Imagen 2 的核心,还是复杂的神经网络架构。经过微调的 Transformer 模型,在文本理解和图像合成上,都表现出了无与伦比的性能。
现在,在文生图领域,谷歌又树立了新的标杆。
用自然语言就能生图的模型,又多了一个
现在,除了 DALL・E 3 之外,我们又有了一个仅凭自然语言就能生图的模型!
相比之下,Midjourney 必须用复杂、专业的提示词,在易使用性上已经被两位竞争者甩出了很远。
仅凭简单文本,就能生存多样化的复杂图像,这类 AI 生图模型对于内容创作的影响是极其深远的。
对于依赖视觉内容的行业来说,这彻底改变了游戏规则,大大减少了传统内容制作所需的时间,内容创作者可以以前所未有的速度,制作高质量的视觉效果。

同时,Imagen 2 还具有无可比拟的图像质量和多功能性。
Imagen 2 用到了谷歌最先进的文本到图像扩散技术,生图质量极高、效果逼真,而且和用户的提示具有高度的一致性。
原因在于,它是使用训练数据的自然分布来生成更逼真的图像,而非采用预先编程的样式。

A jellyfish on a dark blue background
水母在深蓝色的背景下悠然漂浮
可以看到,Imagen 2 的图像生成能力非常惊人。
无论是渲染错综复杂的风景、详细的物体,还是奇幻的场景,生成的图像都具有如此高的保真度,以至于它们可以与人类艺术家创作的图像相媲美,甚至直接超越。

Small canvas oil painting of an orange on a chopping board. Light is passing throughorange segments, casting an orange light across part of the chopping board. There is a blueand white cloth in the background. Caustics, bounce light, expressive brush strokes 一小幅油画,描绘了摆放在砧板上的橙子。阳光穿过橙子的切片,柔和的橙色光线洒在砧板上。画的背景是一块蓝白相间的布,画面巧妙地捕捉了光的折射、反射效果,同时展示了画家富有感情的笔触
有网友表示,看到 Imagen 的这张橙子图,真是让我大吃一惊。灯光穿过橙子后的投影,和提示中描述的意境非常吻合!
有人用同样的提示,让 DALL・E 3 生成了同样的橙子油画图,效果比起 Imagen 3 来说,的确弱了不少。

类似的,Midjourney 生成的橙子,在真实感和意境层面,也要差上一截。

诗中意境,一键逼真还原
以往的「文本到图像」模型,通常是根据训练数据集的图像和标题中的详细信息,来生成与用户提示匹配的图像的。
但是它们有一个 bug:对于每张图像和配对的标题,在细节质量和准确性上可能会有很大差异。
为了帮助创建更高质量和更准确的图像、更好地符合用户的提示,Imagen 2 的训练数据集中添加了更多描述,帮助 Imagen 2 学习不同的标题风格,并更好地理解广泛的用户提示。
这种图像标题配对,就有助于 Imagen 2 更好地理解图像和文字之间的关系,大大提高了它对上下文和细微差别的理解。
就比如,美国作家 Phillis Wheatley《晚间赞美诗》中的一句话「溪流潺潺,鸟儿啁啾,空中飘荡着它们混合的音乐」。
诗中绝美的意境,Imagen 2 把要点全抓住了。
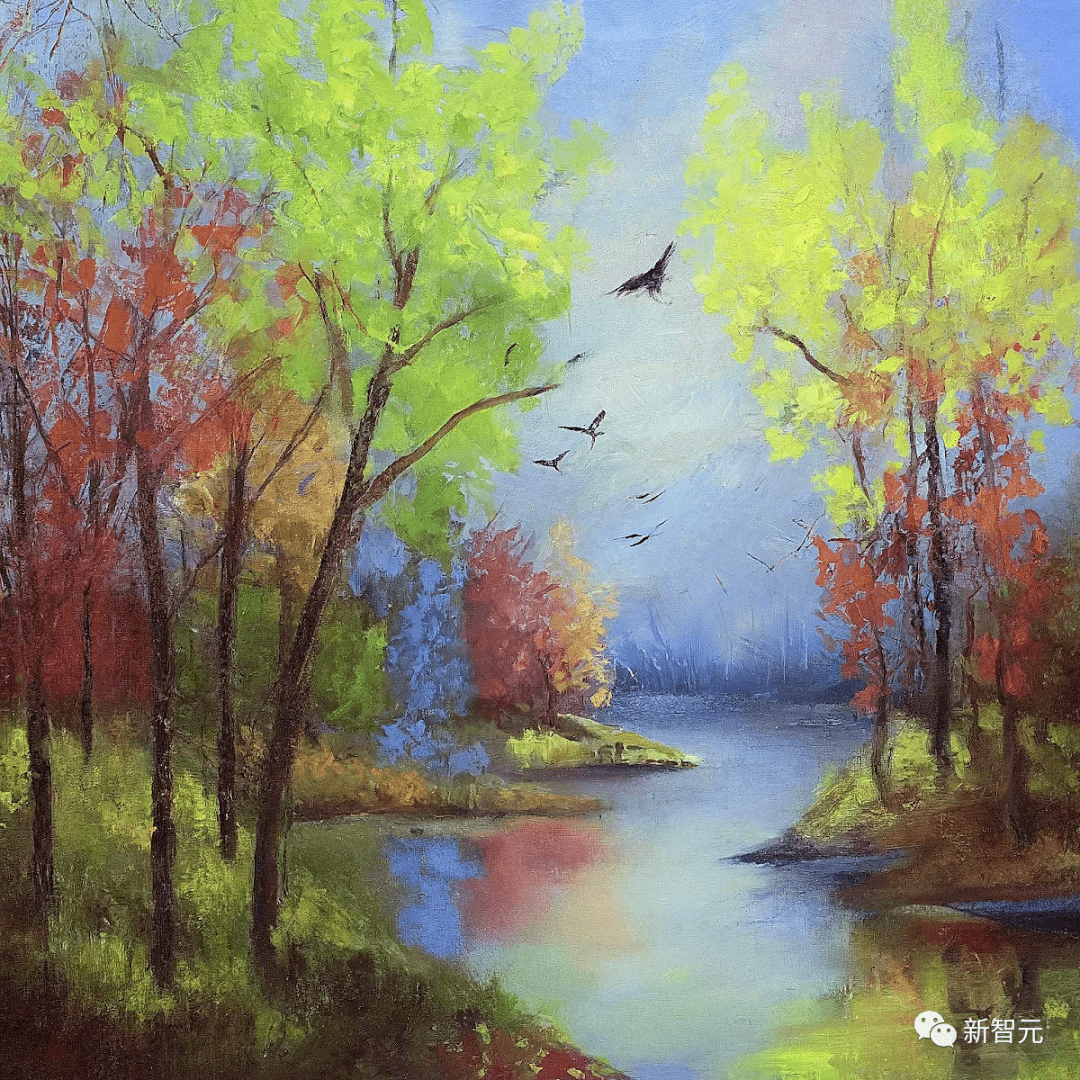
"Soft purl the streams, the birds renew their notes, And through the air their mingledmusic floats." (A Hymn to the Evening by Phillis Wheatley)
相比之下,Midjourney 似乎对于文学描述的内容把握还是欠缺一些,大概率会在图中自动添加一个人物。不过整体画面效果还是不错的。

而到了 DALL・E 3 这里,它居然在图像上加了几行字,生成了一张「贺卡」?

在著名的小说《白鲸记》中,Herman Melville 曾写下「想象一下大海的微妙之处,最可怕的地方在于生物如何在水下滑行,却在大多数情况下不易察觉,并且诡谲地隐藏在最可爱的蔚蓝色调下」。
Imagen 2 也是很懂「海洋文学」的特点。

"Consider the subtleness of the sea, how its most dreaded creatures glide underwater, unapparent for the most part, and treacherously hidden beneath the loveliest tints ofazure." (Moby-Dick by Herman Melville)
相比之下,Midjourney 和 DALL・E 3 一到深海,就瞬间就克苏鲁了起来……

Midjourney

DALL·E 3
儿童文学大家 Frances Hodgson Burnett 所著的《秘密花园》中,对知更鸟有这样一句描述:
知更鸟从缠绕的常春藤上飞到墙头,张开嘴巴,唱出了一个响亮而甜美的颤音,只是为了炫耀自己。世界上就没有什么东西能比它更惹人喜爱了 —— 它们几乎总是这样做。
快看,Imagen 2 生成的这幅画,把常春藤、墙头、唱歌等暗藏的细节,悉数呈现了出来。

"The robin flew from his swinging spray of ivy on to the top of the wall and he openedhis beak and sang a loud, lovely trill, merely to show off. Nothing in the world is quite asadorably lovely as a robin when he shows off - and they are nearly always doing it." (TheSecret Garden by Frances Hodgson Burnett)
同样的提示词,Midjourney 在真实感上还要差上几分。

而 DALL・E 3 相比上面两家,就更逊色了,尤其在植物和羽毛的细节上。

风格复刻,随意变换,更懂人类美学
一直以来,图像生成饱受诟病的问题之一,便是人物的手指生成。
这次,Imagen 2 的数据集和模型进步,在许多领域取得了改进。
其中就包括渲染逼真的手部和人脸,以及保持图像不受干扰的视觉伪影。
同时,谷歌 DeepMind 根据人类对光线、取景、曝光、清晰度等特质的偏好,训练了一个专门的「图像美学模型」。
每张图像都被给予一个美学分数,这有助于调节 Imagen 2 在其训练数据集中赋予人类偏好的图像更多的权重。
这样一来,就提高了 Imagen 2 生成更高质量图像的能力。
使用提示「花」的 AI 生成的图像,美学分数从低(左)到高(右)
Imagen 2 的扩散技术提供了高度的灵活性,使得更容易控制和调整图像的风格。
通过提供参考风格图像并结合文本提示,可以训练 Imagen 2 生成遵循相同风格的新图像。
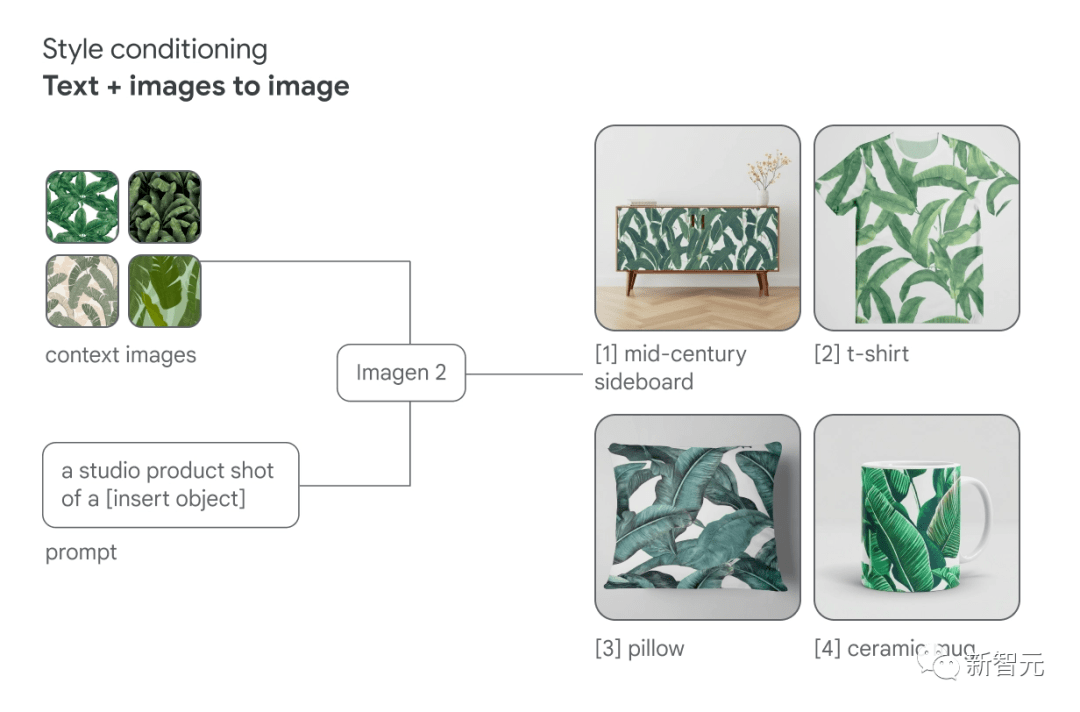
通过使用参考图像和文本提示,Imagen 2 可以更轻松地控制输出样式 更强的「修复」和「扩图」
此外,Imagen 2 还支持图像编辑功能,如「修复」(inpainting)和「扩图」(outpainting)。
通过提供参考图像和图像掩码,我们可以用 inpainting 技术直接在原始图像中生成新内容。
在下面这幅原始图中,只要输入「绿色墙上有一个架子,架子上放着几本书和花瓶」,对应内容就在原图中生成了!
新内容毫不突兀,完美融入原图,浑然天成。
另外,我们还可以使用 outpainting 功能,给原始图像扩图。
夕阳下非洲大草原上长颈鹿和斑马的双人大头贴,一下子就扩成了全身照。
全面加持企业级场景,logo 文案一键生成,中文也支持
现在,谷歌已经 Imagen 2 下放到开发者平台 Vertex AI。
在 Vertex AI 平台上,客户可以使用直观的工具来自定义和部署 Imagen 2,享受全面管理的基础设施和内置的隐私与安全保护。
在谷歌 DeepMind 的技术加持下,Imagen 2 在图像质量上实现了显著提升,帮助开发者根据特定需求创造图像,其中包括:
- 根据自然语言的提示生成高质量、逼真、高分辨率且精美的图像;
- 支持多语言文本渲染,能够在图像中准确添加文本内容;
- 可以设计公司或产品的 Logo,并将其嵌入到图像中;
- 提供视觉问题解答功能,可以从图像中生成标注,或就图像细节提出的问题给出具有信息性的文本回答。
高质量图像:借助于改进的图像和文本理解,以及多种创新的训练和建模技术,Imagen 2 能够生成精准、高品质且逼真的图像。

文本渲染支持:可以根据提示内容,精准地渲染出正确的文本。
Imagen 2 可以在生成含有特定文字或短语的物体图像时,确保输出图像中包含正确短语。

Logo 设计:Imagen 2 能为品牌、产品等生成多种创意和逼真的 Logo,比如徽章、字母甚至非常抽象的 Logo。

标注和问答:利用增强的图像理解能力,Imagen 2 能够创建详细的长文标注,并对图像内元素提出的问题给出详细答案。
多语言提示:除了英语,Imagen 2 还支持其他 6 种语言(中文、印地语、日语、韩语、葡萄牙语、西班牙语),并计划在 2024 年初增加更多语言。这项功能还包括提示与输出之间的翻译能力,比如,可以用西班牙语提示,但指定输出为葡萄牙语。
图像加水印,生成更安全
为了帮助降低文本到图像生成技术的潜在风险和挑战,谷歌从设计和开发到产品部署都设置了强大的护栏。
Imagen 2 集成了 SynthID—— 用于加水印和识别 AI 生成内容的尖端工具包。
这样,Google Cloud 平台的客户可以直接在图像中添加数字水印,同时不会降低图像质量。
不过,即使在对图像进行过滤、裁剪或使用有损压缩方案保存后,SynthID 仍然可以检测出。

除此之外,在向所有用户推出之前,谷歌会进行强大的安全测试,以最大限度地降低伤害风险。
从一开始,谷歌团队就投入对 Imagen 2 的数据安全训练,并添加了技术护栏来限制有问题的输出,如暴力、冒犯或色情内容。
同时,谷歌还对训练数据、输入提示和系统生成的输出进行安全检查。比如正在应用全面的安全过滤器,以避免生成名人图像等有潜在问题的内容。
网友惊呼:真・最强文生图模型来了!
Google DeepMind 研究副总裁兼深度学习主管 Oriol Vinyals 尝试用 Imagen 2 为 Gemini 生成徽标。

另一位谷歌科学家用 Imagen 2 生成的图像如下。

下面是一只网友实测生成的蓝猫。

有网友认为,Imagen 2 是同类产品中最好的。就像 Gemini Ultra 一样,看手和文字就足够了。
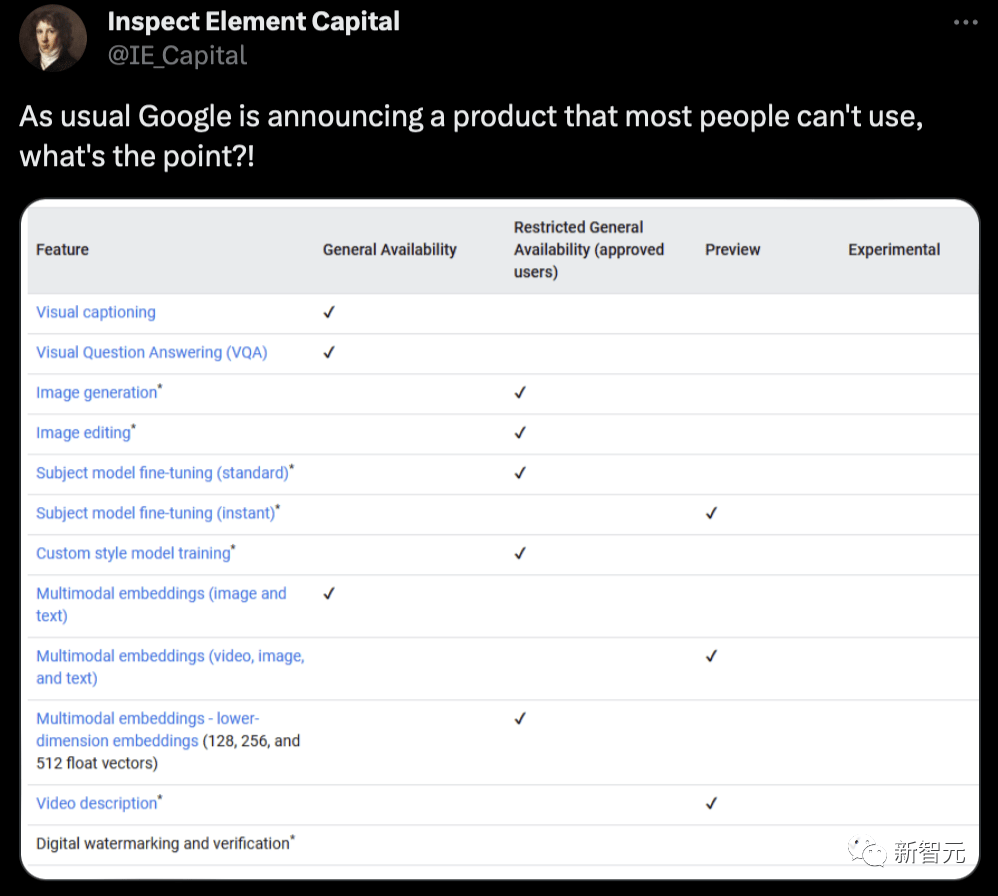
不过,他还吐槽了谷歌不向所有人开放产品的问题。
「像往常一样,谷歌宣布了一款大多数人无法使用的产品,这有什么意义?!」
参考资料:
- https://deepmind.google/technologies/imagen-2/
- https://cloud.google.com/blog/products/ai-machine-learning/imagen-2-on-vertex-ai-is-now-generally-available
广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。
免责声明:本文为转载,非本网原创内容,不代表本网观点。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。






